Jenkins integration example¶
Runperf allows to integrate with Jenkins via xunit results and also can deliver html results with great level of details especially for regression testing. Let me present one example which is not meant to be copy&pasted to your environment, but can serve as an inspiration for integration. An overview might look like this:
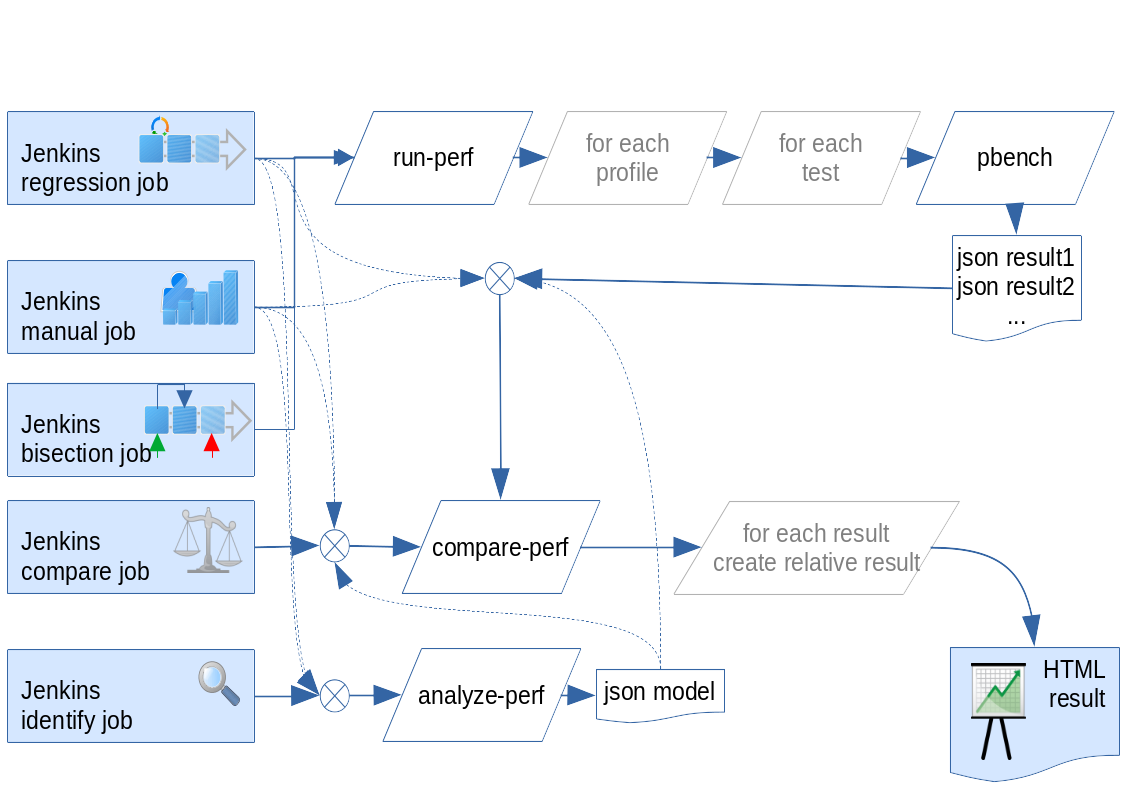
Which might generate following html results (slightly outdated version that compares a different setting on host and guest): here
Let’s imagine we have example.org machine, we can create
rp-example job to run regression testing, then rp-example-manual
job to allow testing of changes or custom params. For each of these
we might want to create $name-ident jobs to allow cherry-picking
and analyzing of results in order to create models to easier evaluate
the expected results.
A useful addition is the rp-analysis job to allow running custom
compare queries without the need to download and run them from your
machines and the rp-prune-artifacts to automatically remove big
tarballs with full results and only keep the json results that are
small and suffice for compare-perf usecases.
The latest addition is an upstream qemu bisect pipeline called
rp-example-upstream-bisect.
The above pipelines are using Jenkins shared library runperf,
which is attached below.
All of these can be easily defined via Jenkins Job Builder:
##############################################################################
# Default configuration
##############################################################################
- defaults:
name: "global"
mailto: ""
wrappers:
- ansicolor
- timestamps
- workspace-cleanup
build-discarder:
days-to-keep: 365
artifact-num-to-keep: 60
# Default runperf params
param-distro: ''
param-guest-distro: ''
param-tests: "'fio:{{\"targets\": \"/fio\"}}' 'uperf:{{\"protocols\": \"tcp\"}}' 'uperf:{{\"protocols\": \"udp\", \"test-types\": \"rr\"}}'"
param-profiles: "Localhost DefaultLibvirt TunedLibvirt"
param-src-build: '1'
param-cmp-tolerance: 5
param-cmp-stddev-tolerance: 10
param-cmp-model-job: ''
param-cmp-model-build: ''
param-host-rpm-from-urls: ''
param-no-reference-builds: 14
param-fio-nbd-setup: false
param-upstream-qemu-commit: ''
param-github-publisher: ''
param-metadata: ''
param-host-script: ''
param-worker-script: ''
param-job: "{name}-run"
trigger-on: "H 17 * * *"
disabled: false
##############################################################################
# Definition for the run-perf execution job
##############################################################################
- job-template:
name: "{name}-run"
triggers:
- timed: "{trigger-on}"
project-type: pipeline
parameters:
- string:
name: DISTRO
description: 'Distribution to be installed/is installed (Fedora-31), when empty latest el8 nightly build is obtained from bkr'
default: "{param-distro}"
- string:
name: GUEST_DISTRO
description: 'Distribution to be installed on guest, when empty "distro" is used'
default: "{param-guest-distro}"
- string:
name: MACHINE
description: 'Machine to be provisioned and tested'
default: "{param-machine}"
- string:
name: ARCH
description: 'Target machine architecture'
default: "{param-arch}"
- string:
name: TESTS
description: 'Space separated list of tests to be executed (WARNING: fio-nbd test requires the FIO_NBD_SETUP checkbox enabled!)'
default: "{param-tests}"
- string:
name: PROFILES
description: 'Space separated list of profiles to be applied'
default: "{param-profiles}"
- string:
name: SRC_BUILD
description: 'Base build to compare with'
default: "{param-src-build}"
- string:
name: CMP_MODEL_JOB
description: 'Job to copy linear "model.json" from'
default: "{param-cmp-model-job}"
- string:
name: CMP_MODEL_BUILD
description: 'Build to copy linear "model.json" from (-1 means lastSuccessful)'
default: "{param-cmp-model-build}"
- string:
name: CMP_TOLERANCE
description: Tolerance for mean values
default: "{param-cmp-tolerance}"
- string:
name: CMP_STDDEV_TOLERANCE
description: Tolerance for standard deviation values
default: "{param-cmp-stddev-tolerance}"
- string:
name: HOST_KERNEL_ARGS
description: Add custom kernel arguments on host
default: ""
- text:
name: HOST_RPM_FROM_URLS
description: 'Specify pages to query for links to RPMs to be installed on host. Works well with koji/brew links to package or build page as well as individually published list of pkgs, also tries to find "$arch/" link and search pkgs there.\n\nThe format is:\n$pkgFilter;$rpmFilter;$urlList\nkernel-[^"]*fc38;!debug|bpftool|kernel-tools|perf|kernel-selftests|kernel-doc;https://koji.fedoraproject.org/koji//packageinfo?packageID=8\nhttps://koji.fedoraproject.org/koji//buildinfo?buildID=2110910\n(\d+);;http://example.com/repos/test/MyRepo/?C=M\;O=D'
default: "{param-host-rpm-from-urls}"
- string:
name: GUEST_KERNEL_ARGS
description: Add custom kernel argsuments on workers/guests
default: ""
- text:
name: GUEST_RPM_FROM_URLS
description: 'Specify pages to query for links to RPMs to be installed on guest. Works well with koji/brew links to package or build page as well as individually published list of pkgs, also tries to find "$arch/" link and search pkgs there.\n\nThe format is:\n$pkgFilter;$rpmFilter;$urlList\nkernel-[^"]*fc38;!debug|bpftool|kernel-tools|perf|kernel-selftests|kernel-doc;https://koji.fedoraproject.org/koji//packageinfo?packageID=8\nhttps://koji.fedoraproject.org/koji//buildinfo?buildID=2110910\n(\d+);;http://example.com/repos/test/MyRepo/?C=M\;O=D'
default: ""
- bool:
name: PBENCH_PUBLISH
description: 'Push the pbench results to company pbench server'
default: "{param-pbench-publish}"
- string:
name: GITHUB_PUBLISHER_PROJECT
description: 'Github publisher project ID (when you want to publish your results)'
default: "{param-github-publisher}"
- bool:
name: FIO_NBD_SETUP
description: 'Compile and install fio with nbd ioengine enabled before test execution'
default: "{param-fio-nbd-setup}"
- string:
name: UPSTREAM_QEMU_COMMIT
description: 'Compile and install qemu using provided commit/tag from the upstream git. Use it by using $PROFILE:{{"qemu_bin": "/usr/local/bin/qemu-system-$ARCH"}} when specifying profiles.'
default: "{param-upstream-qemu-commit}"
- bool:
name: FEDORA_LATEST_KERNEL
description: 'Install the latest kernel from koji (Fedora rpm)'
default: false
- string:
name: METADATA
description: 'Additional run-perf --metadata arguments'
default: "{param-metadata}"
- text:
name: HOST_SCRIPT
description: 'Host script to be executed on all --servers'
default: "{param-host-script}"
- text:
name: WORKER_SCRIPT
description: 'Worker script to be executed on all runperf workers'
default: "{param-worker-script}"
- string:
name: DESCRIPTION_PREFIX
description: Description prefix (describe the difference from default)
default: ""
- string:
name: NO_REFERENCE_BUILDS
description: "Number of reference builds for comparison"
default: "{param-no-reference-builds}"
sandbox: true
pipeline-scm:
scm:
- git:
url: git://PATH_TO_YOUR_REPO_WITH_PIPELINES.git
branches:
- main
script-path: "runperf.groovy"
lightweight-checkout: true
##############################################################################
# Definition for the upstream qemu bisect job
##############################################################################
- job-template:
name: "{name}-bisect-qemu"
project-type: pipeline
parameters:
- string:
name: DISTRO
description: 'Distribution to be installed/is installed (Fedora-31), when empty latest el8 nightly build is obtained from bkr'
default: "{param-distro}"
- string:
name: GUEST_DISTRO
description: 'Distribution to be installed on guest, when empty "distro" is used'
default: "{param-guest-distro}"
- string:
name: MACHINE
description: 'Machine to be provisioned and tested'
default: "{param-machine}"
- string:
name: ARCH
description: 'Target machine architecture'
default: "{param-arch}"
- string:
name: TESTS
description: 'Space separated list of tests to be executed (WARNING: fio-nbd test requires the FIO_NBD_SETUP checkbox enabled!)'
default: "{param-tests}"
- string:
name: PROFILES
description: 'Space separated list of profiles to be applied'
default: "{param-profiles}"
- string:
name: METADATA
description: 'Additional run-perf --metadata arguments'
default: "{param-metadata}"
- text:
name: HOST_SCRIPT
description: 'Host script to be executed on all --servers'
default: "{param-host-script}"
- text:
name: WORKER_SCRIPT
description: 'Worker script to be executed on all runperf workers'
default: "{param-worker-script}"
- string:
name: HOST_KERNEL_ARGS
description: Add custom kernel arguments on host
default: ""
- text:
name: HOST_RPM_FROM_URLS
description: 'Specify pages to query for links to RPMs to be installed on host. Works well with koji/brew links to package or build page as well as individually published list of pkgs, also tries to find "$arch/" link and search pkgs there.\n\nThe format is:\n$pkgFilter;$rpmFilter;$urlList\nkernel-[^"]*fc38;!debug|bpftool|kernel-tools|perf|kernel-selftests|kernel-doc;https://koji.fedoraproject.org/koji//packageinfo?packageID=8\nhttps://koji.fedoraproject.org/koji//buildinfo?buildID=2110910\n(\d+);;http://example.com/repos/test/MyRepo/?C=M\;O=D'
default: "{param-host-rpm-from-urls}"
- string:
name: GUEST_KERNEL_ARGS
description: Add custom kernel argsuments on workers/guests
default: ""
- text:
name: GUEST_RPM_FROM_URLS
description: 'Specify pages to query for links to RPMs to be installed on guest. Works well with koji/brew links to package or build page as well as individually published list of pkgs, also tries to find "$arch/" link and search pkgs there.\n\nThe format is:\n$pkgFilter;$rpmFilter;$urlList\nkernel-[^"]*fc38;!debug|bpftool|kernel-tools|perf|kernel-selftests|kernel-doc;https://koji.fedoraproject.org/koji//packageinfo?packageID=8\nhttps://koji.fedoraproject.org/koji//buildinfo?buildID=2110910\n(\d+);;http://example.com/repos/test/MyRepo/?C=M\;O=D'
default: ""
- bool:
name: PBENCH_PUBLISH
description: 'Push the pbench results to company pbench server'
default: "{param-pbench-publish}"
- bool:
name: FIO_NBD_SETUP
description: 'Compile and install fio with nbd ioengine enabled before test execution'
default: "{param-fio-nbd-setup}"
- bool:
name: TWO_OUT_OF_THREE
description: 'Use 2 out of 3 result evaluation (longer duration, better stability for jittery results)'
default: true
- string:
name: UPSTREAM_QEMU_GOOD
description: 'SHA of the last good (older) upstream qemu.'
default: "{param-upstream-qemu-commit}"
- string:
name: UPSTREAM_QEMU_BAD
description: 'SHA of the last bad (newer) upstream qemu.'
default: "{param-upstream-qemu-commit}"
- string:
name: DESCRIPTION_PREFIX
description: Description prefix (describe the difference from default)
default: ""
sandbox: true
pipeline-scm:
scm:
- git:
url: git://PATH_TO_YOUR_REPO_WITH_PIPELINES.git
branches:
- main
script-path: "upstream_bisect.groovy"
lightweight-checkout: true
##############################################################################
# Definition for a multi-run-perf execution job
##############################################################################
- job-template:
name: "{name}-multi"
project-type: pipeline
parameters:
- string:
name: JOB_NAME
description: 'Name of the run-perf job to be used for triggering the tests.\nWarning: there might be concurrency issues in case one attempts to concurrently schedule jobs!'
default: "{param-job}"
- string:
name: MACHINE
description: 'Machine to be provisioned and tested'
default: "{param-machine}"
- string:
name: ARCH
description: 'Target machine architecture'
default: "{param-arch}"
- string:
name: TESTS
description: 'Space separated list of tests to be executed (WARNING: fio-nbd test requires the FIO_NBD_SETUP checkbox enabled!)'
default: "{param-tests}"
- string:
name: PROFILES
description: 'Space separated list of profiles to be applied'
default: "{param-profiles}"
- string:
name: CMP_MODEL_JOB
description: 'Job to copy linear "model.json" from'
default: "{param-cmp-model-job}"
- string:
name: CMP_MODEL_BUILD
description: 'Build to copy linear "model.json" from (-1 means lastSuccessful)'
default: "{param-cmp-model-build}"
- string:
name: CMP_TOLERANCE
description: Tolerance for mean values
default: "{param-cmp-tolerance}"
- string:
name: CMP_STDDEV_TOLERANCE
description: Tolerance for standard deviation values
default: "{param-cmp-stddev-tolerance}"
- bool:
name: FIO_NBD_SETUP
description: 'Compile and install fio with nbd ioengine enabled before test execution'
default: "{param-fio-nbd-setup}"
- string:
name: DESCRIPTION_PREFIX
description: Description prefix (describe the difference from default)
default: ""
- bool:
name: PBENCH_PUBLISH
description: 'Push the pbench results to company pbench server'
default: "{param-pbench-publish}"
- string:
name: GITHUB_PUBLISHER_PROJECT
description: 'Github publisher project ID (when you want to publish your results)'
default: ""
- text:
name: HOST_SCRIPT
description: 'Host script to be executed on all --servers'
default: "{param-host-script}"
- text:
name: WORKER_SCRIPT
description: 'Worker script to be executed on all runperf workers'
default: "{param-worker-script}"
- string:
name: NO_ITERATIONS
description: 'How many times to run each iteration'
default: ''
- string:
name: DISTROS
description: '`;` separated list of distributions to be installed/is installed (Fedora-31), when empty latest el8 nightly build is obtained from bkr, when `..` is used it uses bkr to fill all available versions in between the specified versions'
default: "{param-distro}"
- string:
name: GUEST_DISTROS
description: '`;` separated list of distribution to be installed on guest, when empty "distro" is used, when `..` is used it uses bkr to fill all available versions in between the specified versions'
default: "{param-guest-distro}"
- string:
name: HOST_KERNEL_ARGSS
description: '`;` separated list of Add custom kernel arguments on host'
default: ""
- text:
name: HOST_RPM_FROM_URLSS
description: 'Double enter (\\n\\n) separated list of Single enter (\\n) separated list of pages to query for links to RPMs to be installed on host. Works well with koji/brew links to package or build page as well as individually published list of pkgs, also tries to find "$arch/" link and search pkgs there.\n\nThe format is:\n$pkgFilter;$rpmFilter;$urlList\nkernel-[^"]*fc38;!debug|bpftool|kernel-tools|perf|kernel-selftests|kernel-doc;https://koji.fedoraproject.org/koji//packageinfo?packageID=8\nhttps://koji.fedoraproject.org/koji//buildinfo?buildID=2110910\n(\d+);;http://example.com/repos/test/MyRepo/?C=M\;O=D'
default: "{param-host-rpm-from-urls}"
- string:
name: GUEST_KERNEL_ARGSS
description: '`;` separated list of custom kernel argsuments on workers/guests'
default: ""
- text:
name: GUEST_RPM_FROM_URLSS
description: 'Double enter (\\n\\n) separated list of Single enter (\\n) separated list of pages to query for links to RPMs to be installed on guest. Works well with koji/brew links to package or build page as well as individually published list of pkgs, also tries to find "$arch/" link and search pkgs there.\n\nThe format is:\n$pkgFilter;$rpmFilter;$urlList\nkernel-[^"]*fc38;!debug|bpftool|kernel-tools|perf|kernel-selftests|kernel-doc;https://koji.fedoraproject.org/koji//packageinfo?packageID=8\nhttps://koji.fedoraproject.org/koji//buildinfo?buildID=2110910\n(\d+);;http://example.com/repos/test/MyRepo/?C=M\;O=D'
default: ""
- string:
name: UPSTREAM_QEMU_COMMITS
description: '`;` separated list of qemu commit/tags to be deployed from the upstream git. Use it by using $PROFILE:{{"qemu_bin": "/usr/local/bin/qemu-system-$ARCH"}} when specifying profiles.'
default: "{param-upstream-qemu-commit}"
sandbox: true
pipeline-scm:
scm:
- git:
url: git://PATH_TO_YOUR_REPO_WITH_PIPELINES.git
branches:
- main
script-path: "multi_runperf.groovy"
lightweight-checkout: true
##############################################################################
# Definition for a bisecter job
##############################################################################
- job-template:
name: "{name}-bisecter"
project-type: pipeline
parameters:
- string:
name: JOB_NAME
description: 'Name of the run-perf job to be used for triggering the tests.\nWarning: there might be concurrency issues in case one attempts to concurrently schedule jobs!'
default: "{param-job}"
- string:
name: MACHINE
description: 'Machine to be provisioned and tested'
default: "{param-machine}"
- string:
name: ARCH
description: 'Target machine architecture'
default: "{param-arch}"
- string:
name: TESTS
description: 'Space separated list of tests to be executed (WARNING: fio-nbd test requires the FIO_NBD_SETUP checkbox enabled!)'
default: "{param-tests}"
- string:
name: PROFILES
description: 'Space separated list of profiles to be applied'
default: "{param-profiles}"
- string:
name: CMP_MODEL_JOB
description: 'Job to copy linear "model.json" from'
default: "{param-cmp-model-job}"
- string:
name: CMP_MODEL_BUILD
description: 'Build to copy linear "model.json" from (-1 means lastSuccessful)'
default: "{param-cmp-model-build}"
- string:
name: CMP_TOLERANCE
description: Tolerance for mean values
default: "{param-cmp-tolerance}"
- string:
name: CMP_STDDEV_TOLERANCE
description: Tolerance for standard deviation values
default: "{param-cmp-stddev-tolerance}"
- bool:
name: FIO_NBD_SETUP
description: 'Compile and install fio with nbd ioengine enabled before test execution'
default: "{param-fio-nbd-setup}"
- string:
name: DESCRIPTION_PREFIX
description: Description prefix (describe the difference from default)
default: ""
- bool:
name: PBENCH_PUBLISH
description: 'Push the pbench results to company pbench server'
default: "{param-pbench-publish}"
- string:
name: GITHUB_PUBLISHER_PROJECT
description: 'Github publisher project ID (when you want to publish your results)'
default: ""
- string:
name: METADATA
description: 'Additional run-perf --metadata arguments'
default: "{param-metadata}"
- text:
name: HOST_SCRIPT
description: 'Host script to be executed on all --servers'
default: "{param-host-script}"
- text:
name: WORKER_SCRIPT
description: 'Worker script to be executed on all runperf workers'
default: "{param-worker-script}"
- bool:
name: PROVISION
description: 'Provision the machine with "--provisioner Beaker"'
default: false
- string:
name: DISTROS
description: '`;` separated list of distributions to be installed/is installed (Fedora-31), when empty latest el8 nightly build is obtained from bkr, when `..` is used it uses bkr to fill all available versions in between the specified versions'
default: "{param-distro}"
- string:
name: GUEST_DISTROS
description: '`;` separated list of distribution to be installed on guest, when empty "distro" is used, when `..` is used it uses bkr to fill all available versions in between the specified versions'
default: "{param-guest-distro}"
- text:
name: HOST_RPM_FROM_URLS
description: 'Single enter (\\n) separated list of pages to query for links to RPMs to be installed on host. It uses "bisecter -E" format (something like "url://https\\://koji.fedoraproject.org/koji//packageinfo?packageID=8:kernel-5.14:+5")'
default: "{param-host-rpm-from-urls}"
- text:
name: GUEST_RPM_FROM_URLS
description: 'Single enter (\\n) separated list of pages to query for links to RPMs to be installed on worker. It uses "bisecter -E" format (something like "url://https\\://koji.fedoraproject.org/koji//packageinfo?packageID=8:kernel-5.14:+5")'
default: ""
sandbox: true
pipeline-scm:
scm:
- git:
url: git://PATH_TO_YOUR_REPO_WITH_PIPELINES.git
branches:
- main
script-path: "bisecter_bisect.groovy"
lightweight-checkout: true
##############################################################################
# Definition of the analyze-perf job
##############################################################################
- job-template:
name: "rp-analysis-{user}"
project-type: pipeline
concurrent: false
description: |
This job allows to cherry-pick results from runperf job and redo the analysis. It is
not thread-safe, therefor it is advised to copy this job with user-suffix and run
the analysis in series storing the graphs manually before submitting next comparison.
parameters:
- string:
name: SRC_JOB
default: "{param-src-job}"
desciption: Source jenkins job
- string:
name: BUILDS
default: ""
description: "List of space separated build numbers to be analyzed, first build is used as source build (not included in graphs)"
- string:
name: DESCRIPTION
default: ""
description: Description of this analysis
- string:
name: CMP_MODEL_JOB
description: 'Job to copy linear "model.json" from'
default: "{param-cmp-model-job}"
- string:
name: CMP_MODEL_BUILD
description: 'Build to copy linear "model.json" from (-1 means lastSuccessful)'
default: "{param-cmp-model-build}"
- string:
name: CMP_TOLERANCE
description: Tolerance for mean values
default: "{param-cmp-tolerance}"
- string:
name: CMP_STDDEV_TOLERANCE
description: Tolerance for standard deviation values
default: "{param-cmp-stddev-tolerance}"
sandbox: true
pipeline-scm:
scm:
- git:
url: git://PATH_TO_YOUR_REPO_WITH_PIPELINES.git
branches:
- main
script-path: "compareperf.groovy"
lightweight-checkout: true
##############################################################################
# Definition of the analyze-perf job
##############################################################################
- job-template:
name: "{name}-identify"
project-type: pipeline
description: |
This job uses analyze-perf script to create model that can be used to better
evaluate run-perf results.
parameters:
- string:
name: SRC_JOB
default: "{name}-run"
desciption: Source jenkins job
- string:
name: BUILDS
default: ""
description: "List of space separated build numbers to be used"
- string:
name: DESCRIPTION
default: ""
description: Free-form description
- string:
name: EXTRA_ARGS
default: ""
description: Additional analyze-perf arguments, for example -t to override default tolerance
- string:
name: REBASE_MODEL_BUILD
description: 'Build number of this job to be used as "--rebase-model" argument'
default: ""
sandbox: true
pipeline-scm:
scm:
- git:
url: git://PATH_TO_YOUR_REPO_WITH_PIPELINES.git
branches:
- main
script-path: "identify.groovy"
lightweight-checkout: true
##############################################################################
# Definition of the prune artifacts job
##############################################################################
- job-template:
name: "rp-prune-artifacts"
node: master
description: |
Remove the big tar.xz files from oldish results not tagged
as keep-forewer.
triggers:
- timed: "H 06 * * *"
parameters:
- string:
name: JOB
default: "{list,your,runperf,jobs,here,to,clean,them,daily}"
description: Name of the job to be pruned
- string:
name: AGE
default: "{param-age}"
description: How old results should be pruned
builders:
- system-groovy:
command: !include-raw-escape ../scripts/prune_artifacts.groovy
##############################################################################
# Definition of the git-publisher job
##############################################################################
- job-template:
name: "rp-publish-results-git"
description: |
Publish the build result in git so it can be viewed eg. in github
pages
project-type: pipeline
parameters:
- string:
name: JOB
default: ""
description: "Job containing the result"
- string:
name: BUILD
default: ""
description: "Build of the job with the result"
- bool:
name: STATUS
default: false
description: "Status of the comparison (GOOD=true/BAD=false)"
- string:
name: NOTES
default: ""
description: "Notes to be added as description to the result entry"
- string:
name: PROJECT
default: ""
description: "Owner of the results (usually a group/company name + project/machine)"
- string:
name: TAG
default: "all"
description: "Version tag used to split results of different versions/tags"
- bool:
name: STRIP_RESULTS
default: true
description: "Publish stripped results (MB->KB)"
- string:
name: OS_VERSION
default: ""
description: "Override the os version"
- string:
name: QEMU_SHA
defalut: ""
description: "Override the qemu SHA"
pipeline-scm:
scm:
- git:
url: git://PATH_TO_YOUR_REPO_WITH_PIPELINES.git
branches:
- main
script-path: "publish-results-git.groovy"
lightweight-checkout: true
###############################################################################
## Project to define jobs for automated regression jobs on example.org machine
###############################################################################
#- project:
# name: rp-example
# param-machine: "example.org"
# param-arch: "x86_64"
# param-src-build: 1
# param-cmp-model-job: "{name}-identify"
# param-cmp-model-build: -1
# param-pbench-publish: true
# jobs:
# - "{name}-run"
# - "{name}-identify"
#
#
###############################################################################
## Project to define manual jobs for example.org machine
###############################################################################
#- project:
# name: rp-example-manual
# param-machine: "example.org"
# param-arch: "x86_64"
# param-distro: "YOUR STABLE RELEASE"
# param-src-build: 1
# param-cmp-model-job: "rp-example-manual-identify"
# param-cmp-model-build: 1
# param-pbench-publish: false
# trigger-on: ""
# jobs:
# - "{name}-run"
# - "{name}-identify"
# - "{name}-multi":
# param-cmp-model-job: ''
# param-cmp-model-build: ''
#
#
###############################################################################
## Project to allow users to run custom queries out of existing results
###############################################################################
#- project:
# name: rp-analysis
# user:
# - virt
# param-src-job: "rp-example-manual"
# param-cmp-model-job: "rp-example-manual-identify"
# param-cmp-model-build: 1
# jobs:
# - "rp-analysis-{user}"
#
###############################################################################
## Prune artifacts after 14 days, hopefully we would notice and mark/move
## them when full details are needed.
###############################################################################
#- project:
# name: rp-prune-artifacts
# param-age: 14
# jobs:
# - "rp-prune-artifacts"
Now let’s have a look at the runperf.groovy pipeline:
// Pipeline to run runperf and compare to given results
// groovylint-disable-next-line
@Library('runperf') _
// Following `params` have to be defined in job (eg. via jenkins-job-builder)
// Machine to be provisioned and tested
machine = params.MACHINE.trim()
// target machine's architecture
arch = params.ARCH.trim()
// Distribution to be installed/is installed (Fedora-32)
// when empty it will pick the latest available nightly el8
_distro = params.DISTRO.trim()
_distro = _distro ?: 'latest-RHEL-8.0%.n.%'
// Distribution to be installed on guest, when empty "distro" is used
guestDistro = params.GUEST_DISTRO.trim()
// Space separated list of tests to be executed
tests = params.TESTS.trim()
// Space separated list of profiles to be applied
profiles = params.PROFILES.trim()
// Base build to compare with
srcBuild = params.SRC_BUILD.trim()
// Compareperf tollerances
cmpModelJob = params.CMP_MODEL_JOB.trim()
cmpModelBuild = params.CMP_MODEL_BUILD.trim()
cmpTolerance = params.CMP_TOLERANCE.trim()
cmpStddevTolerance = params.CMP_STDDEV_TOLERANCE.trim()
// Add custom kernel arguments on host
hostKernelArgs = params.HOST_KERNEL_ARGS.trim()
// Install rpms from (beaker) urls
hostRpmFromURLs = params.HOST_RPM_FROM_URLS.trim()
// Add custom kernel argsuments on workers/guests
guestKernelArgs = params.GUEST_KERNEL_ARGS.trim()
// Install rpms from (beaker) urls
guestRpmFromURLs = params.GUEST_RPM_FROM_URLS.trim()
// Add steps to fetch, compile and install the upstream fio with nbd ioengine compiled in
fioNbdSetup = params.FIO_NBD_SETUP
// Add steps to checkout, compile and install the upstream qemu from git
upstreamQemuCommit = params.UPSTREAM_QEMU_COMMIT.trim()
// Add steps to install the latest kernel from koji (Fedora rpm)
fedoraLatestKernel = params.FEDORA_LATEST_KERNEL
// Description prefix (describe the difference from default)
descriptionPrefix = params.DESCRIPTION_PREFIX
// Number of reference builds
noReferenceBuilds = params.NO_REFERENCE_BUILDS.toInteger()
// Pbench-publish related options
pbenchPublish = params.PBENCH_PUBLISH
// Github-publisher project ID
githubPublisherProject = params.GITHUB_PUBLISHER_PROJECT.trim()
githubPublisherTag = ''
// Additional run-perf metadata
metadata = params.METADATA
// Custom host/guest setups cript
hostScript = params.HOST_SCRIPT
workerScript = params.WORKER_SCRIPT
// Extra variables
// Provisioner machine
workerNode = 'kubernetes'
// runperf git branch
gitBranch = 'main'
// extra runperf arguments
extraArgs = ''
node(workerNode) {
stage('Preprocess') {
(distro, guestDistro, descriptionPrefix) = runperf.preprocessDistros(_distro, guestDistro,
arch, descriptionPrefix)
currentBuild.description = "${distro} - in progress"
}
stage('Measure') {
runperf.cloneDownstreamConfig(gitBranch)
if (fedoraLatestKernel) {
kernelURL = '\nkernel-;!debug|kernel-selftests|kernel-doc;https://koji.fedoraproject.org/koji//packageinfo?packageID=8'
hostRpmFromURLs += kernelURL
guestRpmFromURLs += kernelURL
}
// Use grubby to update default args on host
hostScript = runperf.setupScript(hostScript, hostKernelArgs, hostRpmFromURLs, arch, fioNbdSetup)
workerScript = runperf.setupScript(workerScript, guestKernelArgs, guestRpmFromURLs, arch, fioNbdSetup)
// Build custom qemu
if (upstreamQemuCommit) {
// Always translate the user input into the actual commit and also get the description
sh 'rm -Rf upstream_qemu'
dir('upstream_qemu') {
sh 'git clone --filter=tree:0 https://gitlab.com/qemu-project/qemu.git .'
upstreamQemuVersion = sh(returnStdout: true,
script: "git rev-parse ${upstreamQemuCommit}").trim()
githubPublisherTag = sh(returnStdout: true,
script: "git describe --tags --always ${upstreamQemuCommit}"
).trim().split('-')[0]
println("Using qemu $githubPublisherTag commit $upstreamQemuVersion")
}
sh '\\rm -Rf upstream_qemu'
hostScript += '\n\n' + String.format(runperf.upstreamQemuScript, upstreamQemuVersion, upstreamQemuVersion)
}
if (hostScript) {
writeFile file: 'host_script', text: hostScript
extraArgs += ' --host-setup-script host_script --host-setup-script-reboot'
}
if (workerScript) {
writeFile file: 'worker_script', text: workerScript
extraArgs += ' --worker-setup-script worker_script'
}
if (pbenchPublish) {
metadata += ' pbench_server_publish=yes'
}
// Using jenkins locking to prevent multiple access to a single machine
lock(machine) {
sh '$KINIT'
status = sh(returnStatus: true,
script: "run-perf ${extraArgs} -v --hosts ${machine} --distro ${distro} " +
"--provisioner Beaker --default-password YOUR_DEFAULT_PASSWORD --profiles ${profiles} " +
'--log run.log --paths ./downstream_config --metadata ' +
"'build=${currentBuild.number}${descriptionPrefix}' " +
"'url=${currentBuild.absoluteUrl}' 'project=YOUR_PROJECT_ID ${currentBuild.projectName}' " +
"'pbench_server=YOUR_PBENCH_SERVER_URL' " +
"'machine_url_base=https://YOUR_BEAKER_URL/view/%(machine)s' " +
"${metadata} -- ${tests}")
}
// Add new-line after runperf output (ignore error when does not exists
sh(returnStatus: true, script: "echo >> \$(echo -n result*)/RUNPERF_METADATA")
stage('Archive results') {
// Archive only "result_*" as we don't want to archive "resultsNoArchive"
sh returnStatus: true, script: 'tar cf - result_* | xz -T2 -7e - > "$(echo result_*)".tar.xz'
archiveArtifacts allowEmptyArchive: true, artifacts: runperf.runperfArchiveFilter
}
if (status) {
runperf.tryOtherDistros(_distro, arch)
runperf.failBuild('Run-perf execution failed',
"run-perf returned non-zero status ($status)",
distro)
}
}
stage('Compare') {
// Get up to noReferenceBuilds json results to use as a reference
referenceBuilds = []
for (build in runperf.getGoodBuildNumbers(env.JOB_NAME)) {
copyArtifacts(filter: runperf.runperfResultsFilter, optional: true,
fingerprintArtifacts: true, projectName: env.JOB_NAME, selector: specific("${build}"),
target: "reference_builds/${build}/")
if (findFiles(glob: "reference_builds/${build}/result*/*/*/*/*.json")) {
referenceBuilds.add("${build}:" + sh(returnStdout: true,
script: "echo reference_builds/${build}/*").trim())
if (referenceBuilds.size() >= noReferenceBuilds) {
break
}
}
}
// Get src build's json results to compare against
copyArtifacts(filter: runperf.runperfResultsFilter, optional: true,
fingerprintArtifacts: true, projectName: env.JOB_NAME, selector: specific(srcBuild),
target: 'src_result/')
// If model build set get the model from it's job
if (cmpModelBuild) {
if (cmpModelBuild == '-1') {
copyArtifacts(filter: runperf.modelJson, optional: false, fingerprintArtifacts: true,
projectName: cmpModelJob, selector: lastSuccessful(), target: runperf.thisPath)
} else {
copyArtifacts(filter: runperf.modelJson, optional: false, fingerprintArtifacts: true,
projectName: cmpModelJob, selector: specific(cmpModelBuild), target: runperf.thisPath)
}
cmpExtra = '--model-linear-regression ' + runperf.modelJson
} else {
cmpExtra = ''
}
// Compare the results and generate html as well as xunit results
sh "mkdir -p '${runperf.htmlPath}'"
status = sh(returnStatus: true,
script: ('compare-perf --log compare.log ' +
'--tolerance ' + cmpTolerance + ' --stddev-tolerance ' + cmpStddevTolerance +
" --xunit ${runperf.resultXml} --html ${runperf.htmlIndex} --html-small-file " + cmpExtra +
' -- src_result/* ' + referenceBuilds.reverse().join(' ') +
' $(find . -maxdepth 1 -type d ! -name "*.tar.*" -name "result*")'))
if (fileExists(runperf.resultXml)) {
if (status) {
// This could mean there were no tests to compare or other failures, interrupt the build
echo "Non-zero exit status: ${status}"
}
} else {
runperf.failBuild('Compare-perf execution failed',
"Missing ${runperf.resultXml}, exit code: ${status}",
distro)
}
}
stage('Postprocess') {
// Build description
currentBuild.description = "${descriptionPrefix}${srcBuild} ${currentBuild.number} ${distro}"
// Store and publish html results
archiveArtifacts allowEmptyArchive: true, artifacts: runperf.htmlIndex
if (fileExists(runperf.htmlPath)) {
publishHTML([allowMissing: true, alwaysLinkToLastBuild: false, keepAll: true, reportDir: runperf.htmlPath,
reportFiles: runperf.htmlFile, reportName: 'HTML Report', reportTitles: ''])
}
// Junit results
junit allowEmptyResults: true, testResults: runperf.resultXml
// Remove the unnecessary big files
sh runperf.runperfArchFilterRmCmd
// Publish the results
if (githubPublisherProject) {
build(job: 'rp-publish-results-git',
parameters: [string(name: 'JOB', value: env.JOB_NAME),
string(name: 'BUILD', value: env.BUILD_NUMBER),
booleanParam(name: 'STATUS', value: status == 0),
string(name: 'NOTES', value: descriptionPrefix),
string(name: 'PROJECT', value: githubPublisherProject),
string(name: 'TAG', value: githubPublisherTag),
booleanParam(name: 'STRIP_RESULTS', value: true)],
quietPeriod: 0,
wait: false)
}
}
}
Following compareperf.groovy pipeline is extremely useful for later
analysis, or extra comparison of manual pipelines:
// Pipeline to create comparison of previously generated runperf results
// Following `params` have to be defined in job (eg. via jenkins-job-builder)
// groovylint-disable-next-line
@Library('runperf') _
// Source jenkins job
srcJob = params.SRC_JOB.trim()
// List of space separated build numbers to be analyzed, first build is used
// as source build (not included in graphs)
builds = params.BUILDS.split().toList()
// Description of this analysis
description = params.DESCRIPTION
// Compareperf tollerances
cmpModelJob = params.CMP_MODEL_JOB.trim()
cmpModelBuild = params.CMP_MODEL_BUILD.trim()
cmpTolerance = params.CMP_TOLERANCE.trim()
cmpStddevTolerance = params.CMP_STDDEV_TOLERANCE.trim()
// Extra variables
// Provisioner machine
workerNode = 'kubernetes'
// runperf git branch
gitBranch = 'main'
// misc variables
thisPath = '.'
spaceChr = ' '
lastBuildChr = '-1'
stage('Analyze') {
node(workerNode) {
assert builds.size() >= 2
referenceBuilds = []
// Get all the reference builds (second to second-to-last ones)
if (builds.size() > 2) {
for (build in builds[1..-2]) {
copyArtifacts(filter: runperf.runperfResultsFilter, optional: true,
fingerprintArtifacts: true, projectName: srcJob, selector: specific(build),
target: "reference_builds/${build}/")
if (fileExists("reference_builds/${build}")) {
referenceBuilds.add("${build}:" + sh(returnStdout: true,
script: "echo reference_builds/${build}/*").trim())
} else {
echo "Skipping reference build ${build}, failed to copy artifacts."
}
}
}
// Get the source build
copyArtifacts(filter: runperf.runperfResultsFilter, optional: false,
fingerprintArtifacts: true, projectName: srcJob, selector: specific(builds[0]),
target: 'src_result/')
// Get the destination build
copyArtifacts(filter: runperf.runperfResultsFilter, optional: false,
fingerprintArtifacts: true, projectName: srcJob, selector: specific(builds[-1]),
target: thisPath)
// Get the model
if (cmpModelBuild) {
if (cmpModelBuild == lastBuildChr) {
copyArtifacts(filter: runperf.modelJson, optional: false, fingerprintArtifacts: true,
projectName: cmpModelJob, selector: lastSuccessful(), target: thisPath)
} else {
copyArtifacts(filter: runperf.modelJson, optional: false, fingerprintArtifacts: true,
projectName: cmpModelJob, selector: specific(cmpModelBuild), target: thisPath)
}
cmpExtra = '--model-linear-regression ' + runperf.modelJson
} else {
cmpExtra = ''
}
status = 0
lock(workerNode) {
// Avoid modifying workerNode's environment while executing compareperf
status = sh(returnStatus: true,
script: ('compare-perf -vvv --tolerance ' + cmpTolerance +
' --stddev-tolerance ' + cmpStddevTolerance +
' --xunit ' + runperf.resultXml + ' --html ' + runperf.htmlIndex + spaceChr +
cmpExtra + ' -- src_result/* ' + referenceBuilds.join(spaceChr) +
' $(find . -maxdepth 1 -type d ! -name "*.tar.*" -name "result*")'))
}
if (fileExists(runperf.resultXml)) {
if (status) {
// This could mean there were no tests to compare or other failures, interrupt the build
echo "Non-zero exit status: ${status}"
}
} else {
currentBuild.result = 'FAILED'
error "Missing ${runperf.resultXml}, exit code: ${status}"
}
currentBuild.description = "${description}${builds} ${srcJob}"
archiveArtifacts allowEmptyArchive: true, artifacts: runperf.htmlIndex
junit allowEmptyResults: true, testResults: runperf.resultXml
if (fileExists(runperf.htmlPath)) {
publishHTML([allowMissing: true, alwaysLinkToLastBuild: false, keepAll: true, reportDir: runperf.htmlPath,
reportFiles: runperf.htmlFile, reportName: 'HTML Report', reportTitles: ''])
}
// Remove the unnecessary big files
sh '\\rm -Rf result* src_result* reference_builds'
}
}
And the identify.groovy to allow creating linear models:
// Pipeline to create comparison of previously generated runperf results
// groovylint-disable-next-line
@Library('runperf') _
// Following `params` have to be defined in job (eg. via jenkins-job-builder)
// Source jenkins job
srcJob = params.SRC_JOB
// List of space separated build numbers to be analyzed, first build is used
// as source build (not included in graphs)
builds = params.BUILDS.split().toList()
// Description of this analysis
description = params.DESCRIPTION
// Extra AnalyzePerf arguments
extraArgs = params.EXTRA_ARGS
// Build number used for --rebase-model
rebaseModelBuild = params.REBASE_MODEL_BUILD
// Extra variables
// Provisioner machine
workerNode = 'kubernetes'
// runperf git branch
gitBranch = 'main'
// misc variables
spaceChr = ' '
stage('Analyze') {
node(workerNode) {
// Get all the specified builds
for (build in builds) {
copyArtifacts(filter: 'result*/**/result*.json', optional: false, fingerprintArtifacts: true,
projectName: srcJob, selector: specific(build), target: 'results/')
}
// If rebaseModel set, get the model from that build
if (rebaseModelBuild) {
copyArtifacts(filter: runperf.modelJson, optional: false, fingerprintArtifacts: true,
projectName: env.JOB_NAME, selector: specific(rebaseModelBuild),
target: 'src_model/')
extraArgs += " --rebase-model 'src_model/$runperf.modelJson'"
}
status = 0
lock(workerNode) {
// Avoid modifying workerNode's environment while executing compareperf
status = sh(returnStatus: true,
script: ('analyze-perf -vvv --stddev-linear-regression ' +
runperf.modelJson + spaceChr + extraArgs + ' -- results/*'))
}
if (fileExists(runperf.modelJson)) {
// This could mean there were no tests to compare or other failures, interrupt the build
if (status) {
echo "Non-zero exit status: ${status}"
}
} else {
currentBuild.result = 'FAILED'
error "Missing ${runperf.modelJson}, exit code: ${status}"
}
if (description) {
currentBuild.description = description + spaceChr + builds.join(spaceChr)
} else {
currentBuild.description = builds.join(spaceChr)
}
archiveArtifacts allowEmptyArchive: true, artifacts: runperf.modelJson
sh '\\rm -Rf results*'
}
}
The cleanup job prune_artifacts.py:
#!/bin/env python3
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 2 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
#
# See LICENSE for more details.
#
# Copyright: Red Hat Inc. 2020
# Author: Lukas Doktor <ldoktor@redhat.com>
"""
When executed on a jenkins master it allows to walk the results and remove
"*.tar.*" files on older builds that are not manually marked as
keep-for-infinity.
"""
import time
import glob
import os
import re
JENKINS_DIR = "/var/lib/jenkins/jobs/"
def prune_result(path, before):
"""
Prune result if older than age and keep forever not set
"""
build_path = os.path.join(path, "build.xml")
if not os.path.exists(build_path):
print("KEEP %s - no build.xml" % path)
return
treated_path = os.path.join(path, "ld_artifact_pruned")
if os.path.exists(treated_path):
print("SKIP %s - already treated" % path)
return
with open(build_path) as build_fd:
build_xml = build_fd.read()
if "<keepLog>false</keepLog>" not in build_xml:
print("KEEP %s - keep forever set" % path)
return
match = re.findall(r"<startTime>(\d+)</startTime>", build_xml)
if not match:
print("KEEP %s - no startTime\n%s" % (path, build_xml))
return
start_time = int(match[-1])
if start_time > before:
print("KEEP %s - younger than %s (%s)" % (path, before, start_time))
return
print("PRUNE %s (%s)" % (path, start_time))
for pth in glob.glob(os.path.join(path, "archive", "*.tar.*")):
os.unlink(pth)
with open(treated_path, 'wb'):
"""touching the file"""
def prune_results(job, age):
"""
Walk job's builds and prune them
"""
if not job:
print("No job specified, returning")
return
# Jenkins stores startTime * 1000
before = int((time.time() - age) * 1000)
print("Pruning %s builds older than %s" % (job, before))
builds = glob.glob(os.path.join(JENKINS_DIR, job, "builds", "*"))
for build in builds:
prune_result(build, before)
print("Done")
if __name__ == '__main__':
prune_results(os.environ.get('JOB'),
int(os.environ.get('AGE', 14)) * 86400)
And a bisect job upstream_bisect.groovy:
// Pipeline to run runperf and compare to given results
// groovylint-disable-next-line
@Library('runperf') _
// Following `params` have to be defined in job (eg. via jenkins-job-builder)
// Machine to be provisioned and tested
machine = params.MACHINE.trim()
// target machine's architecture
arch = params.ARCH.trim()
// Distribution to be installed/is installed (Fedora-32)
// when empty it will pick the latest available nightly el8
distro = params.DISTRO.trim()
// Distribution to be installed on guest, when empty "distro" is used
guestDistro = params.GUEST_DISTRO.trim()
// Space separated list of tests to be executed
tests = params.TESTS.trim()
// Space separated list of profiles to be applied
profiles = params.PROFILES.trim()
// Add custom kernel arguments on host
hostKernelArgs = params.HOST_KERNEL_ARGS.trim()
// Install rpms from (beaker) urls
hostRpmFromURLs = params.HOST_RPM_FROM_URLS.trim()
// Add custom kernel argsuments on workers/guests
guestKernelArgs = params.GUEST_KERNEL_ARGS.trim()
// Install rpms from (beaker) urls
guestRpmFromURLs = params.GUEST_RPM_FROM_URLS.trim()
// Add steps to fetch, compile and install the upstream fio with nbd ioengine compiled in
fioNbdSetup = params.FIO_NBD_SETUP
// Specify the bisection range
// Older commit
upstreamQemuGood = params.UPSTREAM_QEMU_GOOD.trim()
// Newer commit
upstreamQemuBad = params.UPSTREAM_QEMU_BAD.trim()
// Description prefix (describe the difference from default)
descriptionPrefix = params.DESCRIPTION_PREFIX
// Pbench-publish related options
pbenchPublish = params.PBENCH_PUBLISH
// Custom host/guest setups cript
hostScript = params.HOST_SCRIPT
workerScript = params.WORKER_SCRIPT
// Extra variables
// Provisioner machine
workerNode = 'kubernetes'
// runperf git branch
gitBranch = 'main'
// extra runperf arguments
extraArgs = ''
String getBkrInstallCmd(String hostBkrLinks, String hostBkrLinksFilter, String arch) {
return ('\nfor url in ' + hostBkrLinks + '; do dnf install -y --allowerasing ' +
'$(curl -k \$url | grep -o -e "http[^\\"]*' + arch + '\\.rpm" -e ' +
'"http[^\\"]*noarch\\.rpm" | grep -v $(for expr in ' + hostBkrLinksFilter + '; do ' +
'echo -n " -e $expr"; done)); done')
}
node(workerNode) {
def contribPath = sh(script: 'runperf-contrib-path', returnStdout: true).trim()
stage('Preprocess') {
(distro, guestDistro, descriptionPrefix) = runperf.preprocessDistros(distro, guestDistro,
arch, descriptionPrefix)
currentBuild.description = "${distro} - in progress"
}
stage('Measure') {
runperf.cloneDownstreamConfig(gitBranch)
metadata = ''
hostScript = runperf.setupScript(hostScript, hostKernelArgs, hostRpmFromURLs, arch, fioNbdSetup)
workerScript = runperf.setupScript(workerScript, guestKernelArgs, guestRpmFromURLs, arch, fioNbdSetup)
writeFile file: 'host_script', text: hostScript
setupQemu = String.format(runperf.upstreamQemuScript, upstreamQemuGood, upstreamQemuGood)
writeFile(file: 'host_script_with_qemu',
text: hostScript + '\n\n' + setupQemu)
if (workerScript) {
writeFile file: 'worker_script', text: workerScript
extraArgs += ' --worker-setup-script worker_script'
}
if (pbenchPublish) {
metadata += ' pbench_server_publish=yes'
}
// Using jenkins locking to prevent multiple access to a single machine
lock(machine) {
// Make sure we have the full upstream_qemu cloned (we don't need submodules, thought)
sh 'rm -Rf upstream_qemu/'
sh 'git clone https://gitlab.com/qemu-project/qemu.git upstream_qemu/'
sh '$KINIT'
// First run the provisioning and dummy test to age the machine a bit
sh("run-perf ${extraArgs} -v --hosts ${machine} --distro ${distro} " +
'--host-setup-script host_script_with_qemu --host-setup-script-reboot ' +
'--provisioner Beaker --default-password YOUR_DEFAULT_PASSWORD ' +
'--profiles DefaultLibvirt --paths ./downstream_config --log prejob.log -- ' +
'\'fio:{"runtime": "30", "targets": "/fio", "block-sizes": "4", "test-types": "read", ' +
'"samples": "1"}\'')
// And now run the bisection without reprovisioning
sh("DIFFPERF='diff-perf -v' '${contribPath}/upstream_qemu_bisect.sh' upstream_qemu/ " +
"${upstreamQemuGood} ${upstreamQemuBad} run-perf ${extraArgs} " +
"-v --hosts ${machine} --distro ${distro} --log job.log " +
"--default-password YOUR_DEFAULT_PASSWORD --profiles ${profiles} " +
"--paths ./downstream_config --metadata " +
"'project=virt-perf-ci ${currentBuild.projectName}' " +
"'pbench_server=YOUR_PBENCH_SERVER_URL' " +
"'machine_url_base=https://YOUR_BEAKER_URL/view/%(machine)s' " +
"${metadata} -- ${tests}")
}
}
stage('Postprocess') {
// Build description
currentBuild.description = "${descriptionPrefix} ${currentBuild.number} ${distro}"
// Move results to mimic usual run-perf results path
if (fileExists('.diff-perf/report.html')) {
diffReportPath = 'html/index.html'
sh('mkdir -p html')
sh("mv '.diff-perf/report.html' '$diffReportPath'")
// Store and publish html results
archiveArtifacts allowEmptyArchive: true, artifacts: diffReportPath
publishHTML([allowMissing: true, alwaysLinkToLastBuild: false, keepAll: true, reportDir: 'html/',
reportFiles: 'index.html', reportName: 'HTML Report', reportTitles: ''])
}
// Remove the unnecessary big files
sh "'${contribPath}/bisect.sh' clean"
}
}
And a range job to trigger multiple runperf jobs:
// Pipeline to trigger a series of run-perf jobs to cover a range of params.
// Following `params` have to be defined in job (eg. via jenkins-job-builder)
// groovylint-disable-next-line
@Library('runperf') _
csvSeparator = ';'
doubleEnter = '\n\n'
// SHARED VALUES FOR ALL JOBS
// Job name to be triggered
jobName = params.JOB_NAME.trim()
// Machine to be provisioned and tested
machine = params.MACHINE.trim()
// target machine's architecture
arch = params.ARCH.trim()
// Space separated list of tests to be executed
tests = params.TESTS.trim()
// Space separated list of profiles to be applied
profiles = params.PROFILES.trim()
// Compareperf tollerances
cmpModelJob = params.CMP_MODEL_JOB.trim()
cmpModelBuild = params.CMP_MODEL_BUILD.trim()
cmpTolerance = params.CMP_TOLERANCE.trim()
cmpStddevTolerance = params.CMP_STDDEV_TOLERANCE.trim()
// Add steps to fetch, compile and install the upstream fio with nbd ioengine compiled in
fioNbdSetup = params.FIO_NBD_SETUP
// Description prefix (describe the difference from default)
descriptionPrefix = params.DESCRIPTION_PREFIX
// Pbench-publish related options
pbenchPublish = params.PBENCH_PUBLISH
// Github-publisher project ID
githubPublisherProject = params.GITHUB_PUBLISHER_PROJECT.trim()
// LIST OF VALUES
// Iterations of each combination
if (params.NO_ITERATIONS) {
iterations = (1..params.NO_ITERATIONS.toInteger()).toList()
} else {
iterations = [1]
}
// Distribution to be installed/is installed (Fedora-32)
// when empty it will pick the latest available nightly el8
distrosRaw = params.DISTROS.split(csvSeparator)
// Distribution to be installed on guest, when empty "distro" is used
guestDistrosRaw = params.GUEST_DISTROS.split(csvSeparator)
// Add custom kernel arguments on host
hostKernelArgss = params.HOST_KERNEL_ARGSS.split(csvSeparator)
// Install rpms from (beaker) urls
hostRpmFromURLss = params.HOST_RPM_FROM_URLSS.trim().split(doubleEnter)
// Add custom kernel argsuments on workers/guests
guestKernelArgss = params.GUEST_KERNEL_ARGSS.split(csvSeparator)
// Install rpms from (beaker) urls
guestRpmFromURLss = params.GUEST_RPM_FROM_URLSS.trim().split(doubleEnter)
// Add steps to checkout, compile and install the upstream qemu from git
upstreamQemuCommits = params.UPSTREAM_QEMU_COMMITS.split(csvSeparator)
// Custom host/guest setups cript
hostScript = params.HOST_SCRIPT
workerScript = params.WORKER_SCRIPT
// Extra variables
// Provisioner machine
workerNode = 'kubernetes'
// misc variables
srcBuildUnset = '-1'
distros = runperf.getDistrosRange(distrosRaw, workerNode, arch)
guestDistros = runperf.getDistrosRange(guestDistrosRaw, workerNode, arch)
referenceBuilds = 0
srcBuild = srcBuildUnset
paramTypes = [iterations, hostRpmFromURLss, guestKernelArgss, guestRpmFromURLss, hostKernelArgss,
upstreamQemuCommits, guestDistros, distros]
for (params in paramTypes.combinations()) {
println("Triggering with: $params")
if (params[0] == 1) {
prefix = descriptionPrefix
} else {
prefix = "${descriptionPrefix}${params[0]}"
}
// TODO: Add no-provisioning-version
// Use a cleanup job to remove host-setup-script things
srcBuild = runperf.triggerRunperf(env.JOB_NAME, srcBuild == srcBuildUnset, params[7], params[6],
machine, arch, tests, profiles, srcBuild, params[4],
params[1], params[2], params[3],
params[5], prefix, pbenchPublish,
fioNbdSetup, Math.max(0, referenceBuilds).toString(),
cmpModelJob, cmpModelBuild, cmpTolerance, cmpStddevTolerance,
githubPublisherProject, hostScript, workerScript)
referenceBuilds += 1
}
To enable the Jenkins shared libraries look at Extending with Shared Libraries tutorial. Once you have your repo enabled, place the following file:
import groovy.transform.Field
import java.util.regex.Pattern
// Use this by adding: @Library('runperf') _
// misc variables
@Field String resultXml = 'result.xml'
@Field String htmlPath = 'html'
@Field String htmlFile = 'index.html'
@Field String htmlIndex = "${htmlPath}/${htmlFile}"
@Field String modelJson = 'model.json'
@Field String thisPath = '.'
@Field String runperfArchiveFilter = ('result*/*/*/*/*.json,result*/RUNPERF_METADATA,result*/**/__error*__/**,' +
'result*/**/__sysinfo*__/**,result_*.tar.xz,*.log')
@Field String runperfArchFilterRmCmd = "\\rm -Rf result* src_result* reference_builds ${htmlPath} *.log"
@Field String runperfResultsFilter = 'result*/*/*/*/*.json,result*/RUNPERF_METADATA,result*/**/__error*__/**'
@Field String makeInstallCmd = '\nmake -j $(getconf _NPROCESSORS_ONLN)\nmake install'
@Field String kojiUrl = 'https://koji.fedoraproject.org/koji/'
@Field String fioNbdScript = ('\n\n# FIO_NBD_SETUP' +
'\ndnf install --skip-broken -y fio gcc zlib-devel libnbd-devel make qemu-img libaio-devel' +
'\ncd /tmp' +
'\ncurl -L https://github.com/axboe/fio/archive/refs/tags/fio-3.34.tar.gz | tar xz' +
'\ncd fio-fio-3.34' +
'\n./configure --enable-libnbd\n' +
makeInstallCmd +
'\nmkdir -p /var/lib/runperf/' +
'\necho "fio 3.34" >> /var/lib/runperf/sysinfo')
// Usage: String.format(upstreamQemuScript, upstreamCommit, upstreamCommit)
@Field String upstreamQemuScript = """# UPSTREAM_QEMU_SETUP
OLD_PWD="\$PWD"
dnf install --skip-broken -y python3-devel zlib-devel gtk3-devel glib2-static spice-server-devel usbredir-devel make gcc libseccomp-devel numactl-devel libaio-devel git ninja-build python3-tomli
cd /root
[ -e "qemu" ] || { mkdir qemu; cd qemu; git init; git remote add origin https://gitlab.com/qemu-project/qemu.git; cd ..; }
cd qemu
git fetch --depth=1 origin %s
git checkout -f %s
git submodule update --init
VERSION=\$(git rev-parse HEAD)
git diff --quiet || VERSION+="-dirty"
./configure --target-list="\$(uname -m)"-softmmu --disable-werror --enable-kvm --enable-vhost-net --enable-attr --enable-fdt --enable-vnc --enable-seccomp --enable-usb-redir --disable-opengl --disable-virglrenderer --with-pkgversion="\$VERSION"
$makeInstallCmd
chcon -Rt qemu_exec_t /usr/local/bin/qemu-system-"\$(uname -m)"
chcon -Rt virt_image_t /usr/local/share/qemu/
\\cp -f build/config.status /usr/local/share/qemu/
cd \$OLD_PWD"""
@Field String bkrExtraArgs = ' --labcontroller ENTER_LAB_CONTROLLER_URL '
@Field String ownerEmail = 'ENTER_OPERATOR_EMAIL_ADDR
void failBuild(String subject, String details, String distro=distro) {
// Set description, send email and raise exception
currentBuild.description = "BAD ${distro} - $details"
mail(to: ownerEmail,
subject: "${env.JOB_NAME}: $subject",
body: "Job: ${env.BUILD_URL}\n\n$details")
error details
}
List preprocessDistros(String distro, String guestDistro, String arch, descriptionPrefix) {
// Parses the distro and guestDistro params into actual [distro, guestDistro]
if (distro.startsWith('latest-')) {
if (distro.startsWith('latest-untested-')) {
distro = getLatestUntestedDistro(distro[16..-1], arch)
descriptionPrefix += 'U' // To emphasize we use "untested" distros
echo "Using latest-untested distro ${distro} from bkr"
} else {
distro = getLatestDistros(distro[7..-1], 1, arch)[0]
echo "Using latest distro ${distro} from bkr"
}
} else {
echo "Using distro ${distro} from params"
}
if (!guestDistro) {
guestDistro == distro
}
if (guestDistro == distro) {
echo "Using the same guest distro ${distro}"
} else {
echo "Using different guest distro: ${guestDistro} from host: ${distro}"
}
return [distro, guestDistro, descriptionPrefix]
}
void cloneDownstreamConfig(gitBranch) {
// This way we add downstream plugins and other configuration
dir('downstream_config') {
git branch: gitBranch, url: 'git://PATH_TO_YOUR_REPO_WITH_PIPELINES/runperf_config.git'
}
}
@NonCPS
List urlFindRpms(String url, String rpmFilter, String arch) {
// Searches html pages for links to RPMs based on the filter
//
// The filters to find RPMs is ">${rpmFilter}.*($arch|noarch).rpm<"
// and it searches (urlList: https://example.com/rpms):
// 1. the provided $urlList page
// - eg: https://example.com/rpms
// 2. all pages linked from $urlList page using "$arch/?" filter
// - eg: https://example.com/rpms/x86_64
println("urlFindRpms $url $rpmFilter $arch")
def matches
try {
page = new URL(url).text
} catch(java.io.IOException details) {
println("Failed to get url $url")
return []
}
// Look for rpmFilter-ed rpms on base/link/arch/ page
matches = page =~ Pattern.compile("href=\"($rpmFilter[^\"]*(noarch|$arch)\\.rpm)\"[^>]*>[^<]+<")
if (matches.size() > 0) {
// Links found, translate relative path and report it
links = []
matches.each {link ->
links.add(new URL(new URL(url), link[1]).toString())
}
return links
}
// No RPM pkgs found, check if arch link is available
matches = page =~ Pattern.compile("href=\"([^\"]+)\"[^>]*>$arch/?<")
for (match in matches) {
urlTarget = new URL(new URL(url), match[1]).toString()
links = urlFindRpms(urlTarget, rpmFilter, arch)
if (links.size() > 0) {
return links
}
}
// No matches in any $arch link
return []
}
@NonCPS
String cmdInstallRpmsFromURLs(String param, String arch) {
// Wrapper to run urlFindLinksToRpms on jenkins params
//
// The param format is:
// $pkgFilter;$rpmFilter;$urlList\n
// $urlList\n
// ...
//
// Where $pkgFilter and $rpmFilter is Java regular expression or
// one can use '!foo|bar|baz in order to match anything but the
// passed items (translates into "(?!.*(foo|bar|baz))")
allLinks = []
for (String line in param.split('\n')) {
args = line.split("(?<!\\\\);")
if (args.size() == 1) {
// Only $urlList specified
links = urlFindLinksToRpms(args[0].replace('\\;', ';'), '', '', arch)
} else if (args.size() == 3) {
// $urlList, $pkgFilter and $rpmFilter specified
for (i in [0, 1]) {
if (args[i].startsWith("!")) {
// Add simplification for inverse match
args[i] = '(?!.*(' + args[i][1 .. -1] + '))'
}
}
links = urlFindLinksToRpms(args[2].replace('\\;', ';'), args[0].replace('\\;', ';'),
args[1].replace('\\;', ';'), arch)
} else {
println("Incorrect parameter ${line}")
continue
}
if (links.size() > 0) {
for (link in links) {
allLinks.add(link.replace('\n', ''))
}
} else {
println("No matches for $line")
}
}
if (allLinks.size() > 0) {
return 'dnf install -y --allowerasing --skip-broken ' + allLinks.join(' ')
}
return ''
}
@NonCPS
List urlFindLinksToRpms(String urlList, String pkgFilter='', String rpmFilter='', String arch='') {
// Searches html page and it's links for links to RPMs based on the filters
//
// The filters to find RPMs is ">${rpmFilter}.*($arch|noarch).rpm<"
// and it searches (urlList: https://example.com/rpms):
// 1. the provided $urlList page
// - eg: https://example.com/rpms
// 2. all pages linked from $urlList page using "$arch/?" filter
// - eg: https://example.com/rpms/x86_64
// 3. all pages linked from $urlList page using $pkgFilter filter
// - eg: https://example.com/rpms/2023-01-01
// 4. all pages linkef from the $pkgFilter-ed pages using "$arch/?" filter
// - eg: https://example.com/rpms/2023-01-01/x86_64
//
// pkgFilter/rpmFilter uses Java regular expression, you can use things like
// 'kernel' to match "^kernel-XYZ"
// '[^\"]*kernel' to match "whateverkernel-XYZ"
// '(?!.*(debug|doc))[^\"]*extra' to match "whatever-extra-whatever" that does
// not contain "debug", nor "doc"
println("urlFindLinksToRpms $urlList $pkgFilter $rpmFilter $arch")
def matches
// First try looking for RPMs directly on this page
links = urlFindRpms(urlList, rpmFilter, arch)
if (links.size() > 0) {
return links
}
try {
page = new URL(urlList).text
} catch(java.io.IOException details) {
println("Failed to get url $urlList")
return []
}
// Look for pkgFilter-ed links
matches = page =~ Pattern.compile("href=\"([^\"]+)\"[^>]*>$pkgFilter[^<]*<")
for (match in matches) {
urlTarget = new URL(new URL(urlList), match[1]).toString()
links = urlFindRpms(urlTarget, rpmFilter, arch)
if (links) {
return links
}
}
return []
}
List getLatestDistros(String name, Integer limit, String arch) {
// Return latest $limit distros matching the name (use % to match anything)
println("getLatestDistros $name")
distros = sh(returnStdout: true,
script: ('echo -n $(bkr distro-trees-list --arch ' + arch + ' --name=' + name +
' --limit ' + limit + bkrExtraArgs + ' --format json ' +
'| grep \'"distro_name"\' | cut -d\'"\' -f4)'
)).trim().split()
return(distros)
}
@NonCPS
List getTestedDistros(String jobName, String distro) {
// Turn our distro (RHEL-8.0.0-20000000.n.0) into regex (RHEL-d.d.d-dddddddd.n.d)
// (this is unsafe method that leaves the '.' and such, but should do for now)
reNum = '[0-9]'
reDistro = distro.replaceAll(reNum, reNum)
reDistro = reDistro.replaceAll('%', '[^ ]*')
distros = []
for (build in Jenkins.instance.getJob(jobName).builds) {
build?.description?.eachMatch(reDistro) {
dist -> distros.add(dist)
}
}
return(distros)
}
String getLatestUntestedDistro(String distro, String arch) {
// Return latest distro that has not been tested by this job yet
tested_distros = getTestedDistros(env.JOB_NAME, distro)
latest_distros = getLatestDistros(distro, 10, arch)
for (dist in latest_distros) {
if (!(dist in tested_distros)) {
return(dist)
}
}
failBuild('No untested distros to try',
"All past 10 distros were already tested ${latest_distros}")
return("")
}
List getDistroRange(String[] range, String workerNode, String arch) {
// Wrapper to allow "..".split() as well as ["foo", "bar"]]
return(getDistroRange(range.toList(), workerNode, arch))
}
List getDistroRange(List range, String workerNode, String arch) {
// Find all distros between range[0] and range[1] revision (max 100 versions)
println("getDistroRange ${range}")
first = range[0]
last = range[1]
common = ''
for (i = 0; i < Math.min(first.length(), last.length()); i++) {
if (first[i] != last[i]) {
break
}
common += first[i]
}
if (first.contains('n') && last.contains('n')) {
common += '%n'
} else if (first.contains('d') && last.contains('d')) {
common += '%d'
}
node(workerNode) {
distros = getLatestDistros(common + '%', 100, arch).reverse();
distroRange = [];
i = 0;
while (i < distros.size()) {
if (distros[i] == first) {
break;
}
++i;
}
while (i < distros.size()) {
distroRange.add(distros[i]);
if (distros[i++] == last) {
break;
}
}
}
return(distroRange)
}
List getDistrosRange(String[] range, String workerNode, String arch) {
// Wrapper to allow "..".split() as well as ["foo", "bar"]]
return(getDistrosRange(range.toList(), workerNode, arch))
}
List getDistrosRange(List distrosRaw, String workerNode, String arch) {
// Process list of distros and replace '..' ranges with individual versions
println("getDistrosRange ${distrosRaw}")
List distros = []
for (distro in distrosRaw) {
if (distro.contains('..')) {
distroRange = getDistroRange(distro.split('\\.\\.'), workerNode, arch)
println("range ${distroRange}")
distros += distroRange.toList()
} else {
println("add ${distro}")
distros.add(distro)
}
}
return(distros)
}
@NonCPS
List getGoodBuildNumbers(String jobName) {
// Build is non-serializable object, we have to use NonCPS
// on the other hand we can not use copyArtifacts inside NonCPS
// therefore we have to only query for all descriptions and
// then iterate throught them, because we don't know how many
// builds we are going to need (copyArtifacts can fail)
builds = []
for (build in Jenkins.instance.getJob(jobName).builds) {
if (build?.description?.startsWith('BAD')) {
println("skip ${build.description} ${build.number}")
} else {
builds.add(build.number)
if (build?.description?.startsWith('STOP')) {
print("stop processing, STOP build detected ${build.description} ${build.number}")
break
}
}
}
return builds
}
String setupScript(output, kernelArgs, rpmFromURLs, arch, fioNbdSetup) {
// Generate additional parts of the setup script
if (kernelArgs) {
output += "\ngrubby --args '${kernelArgs}' --update-kernel=\$(grubby --default-kernel)"
}
// Ugly way of installing all arch's rpms from a site, allowing a filter
// this is usually used on koji/brew to allow updating certain packages
// warning: It does not work when the url rpm is older.
if (rpmFromURLs) {
output += cmdInstallRpmsFromURLs(rpmFromURLs, arch)
}
// Install deps and compile custom fio with nbd ioengine
if (fioNbdSetup) {
output += fioNbdScript
}
output += '\n'
return output
}
@NonCPS
def triggerRunperf(String jobName, Boolean waitForStart, String distro, String guestDistro,
String machine, String arch, String tests, String profiles, String srcBuild,
String hostKernelArgs, String hostRpmFromURLs,
String guestKernelArgs, String guestRpmFromURLs,
String upstreamQemuCommit, String descriptionPrefix,
Boolean pbenchPublish, Boolean fioNbdSetup, String noReferenceBuilds,
String cmpModelJob, String cmpModelBuild, String cmpTolerance,
String cmpStddevTolerance, String githubPublisherProject, String hostScript,
String workerScript) {
// Trigger a run-perf job setting all of the params according to arguments
// on waitForStart returns the triggered build.id, otherwise it
// returns srcBuild value
parameters = [
new StringParameterValue('DISTRO', distro),
new StringParameterValue('GUEST_DISTRO', guestDistro),
new StringParameterValue('MACHINE', machine),
new StringParameterValue('ARCH', arch),
new StringParameterValue('TESTS', tests),
new StringParameterValue('PROFILES', profiles),
new StringParameterValue('SRC_BUILD', srcBuild),
new StringParameterValue('HOST_KERNEL_ARGS', hostKernelArgs),
new TextParameterValue('HOST_RPM_FROM_URLS', hostRpmFromURLs),
new StringParameterValue('GUEST_KERNEL_ARGS', guestKernelArgs),
new TextParameterValue('GUEST_RPM_FROM_URLS', guestRpmFromURLs),
new StringParameterValue('UPSTREAM_QEMU_COMMIT', upstreamQemuCommit),
new StringParameterValue('DESCRIPTION_PREFIX', descriptionPrefix),
new BooleanParameterValue('PBENCH_PUBLISH', pbenchPublish),
new BooleanParameterValue('FIO_NBD_SETUP', fioNbdSetup),
new StringParameterValue('NO_REFERENCE_BUILDS', noReferenceBuilds),
new StringParameterValue('CMP_MODEL_JOB', cmpModelJob),
new StringParameterValue('CMP_MODEL_BUILD', cmpModelBuild),
new StringParameterValue('CMP_TOLERANCE', cmpTolerance),
new StringParameterValue('CMP_STDDEV_TOLERANCE', cmpStddevTolerance),
new StringParameterValue('GITHUB_PUBLISHER_PROJECT', githubPublisherProject),
new TextParameterValue('HOST_SCRIPT', hostScript),
new TextParameterValue('WORKER_SCRIPT', workerScript)
]
job = Hudson.instance.getJob(jobName)
queue = job.scheduleBuild2(0, new ParametersAction(parameters))
if (waitForStart) {
println('Waiting for build to be scheduled to obtain srcBuild ID')
build = queue.waitForStart()
srcBuild = "${build.id}"
}
// Explicitly clean build, job and queue, otherwise we get CPS failures
build = job = queue = null
return(srcBuild)
}
@NonCPS
void tryOtherDistros(String rawDistro, String arch) {
// Re-trigger the job with another untested distro if possible
String strProvisionFail = 'Provisioning failed'
if (!rawDistro.startsWith('latest-')) {
// Using strict distro version
failBuild(strProvisionFail,
"Provisioning failed, bailing out as we are using strict distro ${rawDistro}")
}
if (rawDistro.startsWith('latest-untested-')) {
latestDistro = rawDistro
} else {
latestDistro = "latest-untested-${rawDistro[7..-1]}"
}
triggerRunperf(env.JOB_NAME, false, latestDistro, params.GUEST_DISTRO, params.MACHINE, params.ARCH,
params.TESTS, params.PROFILES, params.SRC_BUILD, params.HOST_KERNEL_ARGS,
params.HOST_RPM_FROM_URLS, params.GUEST_KERNEL_ARGS,
params.GUEST_RPM_FROM_URLS, params.UPSTREAM_QEMU_COMMIT,
params.DESCRIPTION_PREFIX, params.PBENCH_PUBLISH, params.FIO_NBD_SETUP,
params.NO_REFERENCE_BUILDS, params.CMP_MODEL_JOB, params.CMP_MODEL_BUILD,
params.CMP_TOLERANCE, params.CMP_STDDEV_TOLERANCE, params.GITHUB_PUBLISHER_PROJECT,
params.HOST_SCRIPT, params.WORKER_SCRIPT)
}
@NonCPS
def getBuildEnv(String jobName, String buildName) {
env = Hudson.instance.getJob(jobName).getBuildByNumber(buildName as int).getEnvironment()
str_env = "${env}"
env = null
return str_env
}
into $YOUR_SHARED_LIB_REPO/vars/runperf.groovy and you
should be good to go. Feel free to ping me if anything
goes wrong.